This article introduces the ApsaraDB Data Agent Enterprise Edition, an AI-powered assistant that enables natural language data analysis and end-to-end automation for enterprises.

This article introduces Alibaba Cloud ClickHouse's Agent-lens, an enterprise-grade observability solution for monitoring, evaluating, and controlling autonomous AI agents.

Alibaba Cloud database updates for June 2026 focus on practical wins.

This article introduces Alibaba Cloud's DataBridge Agent, which automates multi-source data collection and structuring to power AI models and workflows.

This article discusses the benefits of PolarDB and explains how to claim resources for free.

This article details how PolarDB-X optimizes pagination on massive distributed tables using partition pruning, late materialization, and deterministic indexing.

This article introduces PolarDB-X's Secondary Prefix Compression (SPC), which shrinks secondary indexes by up to 70% to boost I/O performance.

This article introduces ApsaraDB RDS for MySQL 8.4, highlighting its extended long-term support, seamless backward compatibility, and deep AliSQL kernel optimizations for enterprise workloads.

This article provides a practical guide to multi-tenant data isolation and performance optimization using PolarDB for PostgreSQL Distributed Edition.

This article introduces RDSHermes, a secure and self-evolving database-native AI agent service on ApsaraDB for RDS.

DAS Agent, MCP Server, and Dify are integrated to implement unified and intelligent O&M for database instances across Alibaba Cloud accounts.

This article introduces RDSClaw's database management feature, enabling secure natural-language interaction with databases without writing SQL.
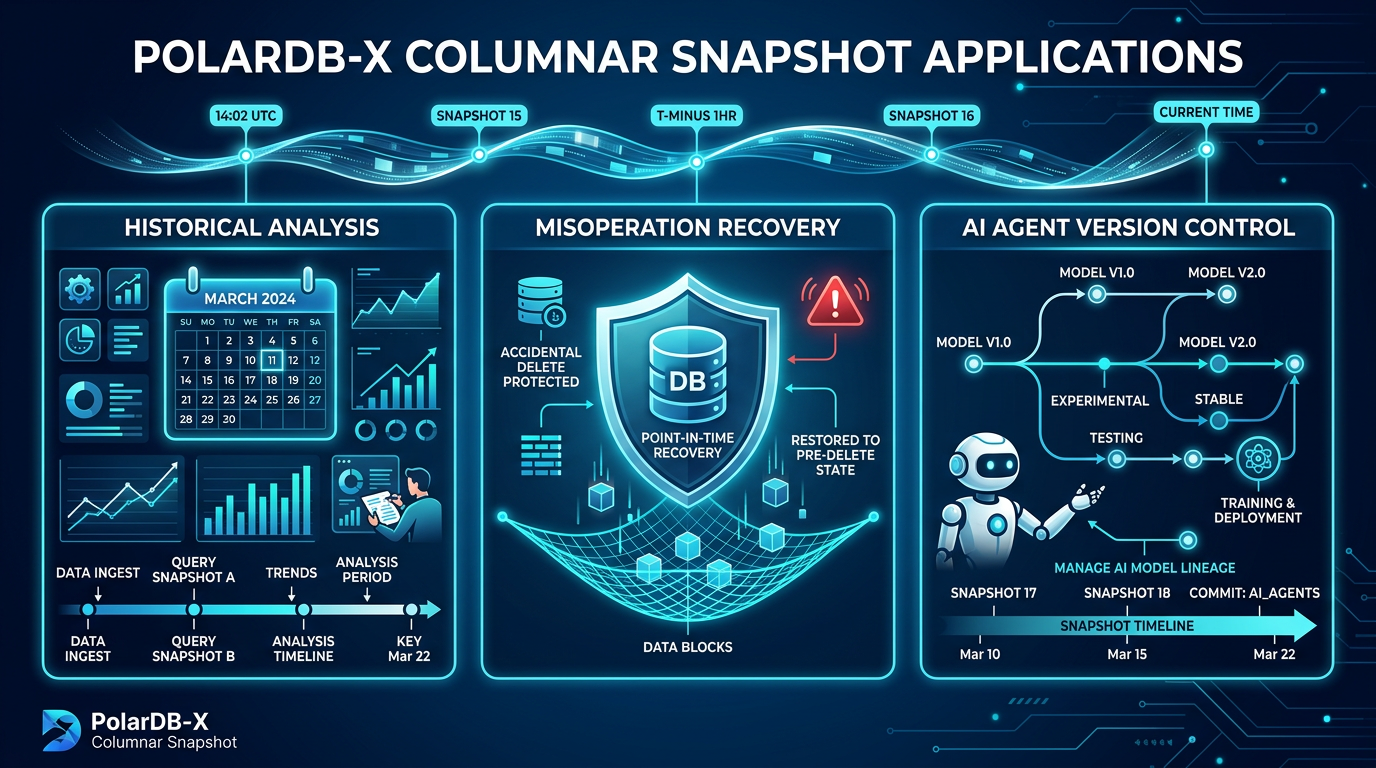
This article introduces practical applications of PolarDB-X columnar snapshots for historical analysis, rapid data recovery, and AI agent version management.
This article introduces the fully-managed PolarDB-X Mem0 service, which provides AI agents with long-term memory through a unified dual-channel architecture for both semantic and structured data.

This article introduces AgenticDB, an AI-native data foundation built on AnalyticDB for managing AI agent context and backend services.

This article introduces PolarDB-X Skill, an AI tool that automatically designs optimal table partitioning solutions using natural language.

This article introduces advanced, production-grade Alibaba Cloud features that help engineers build resilient, hyper-scale infrastructure.
We're excited to announce the general availability of AI-Native Database Service (AIDBS) — a unified platform that transforms your existing Alibaba Cl...

April 2026 brought a strong wave of AI-native capabilities across Alibaba Cloud database portfolio. Highlights include Lindorm AI Engine for in-databa.

Discover the latest database product updates for March 2026 in our informative infographic!


