June 2026 Alibaba Cloud Big Data & AI Newsletter: Tech updates, new releases, market trends, and customer practices.

Powered by Quick BI, Alibaba Cloud has become the only Chinese BI vendor named in the Gartner® Magic Quadrant for Analytics and Business Intelligence .

This article introduces Alibaba Cloud ApsaraMQ for Kafka's new zero-ETL data lake ingestion capability, enabling one-click routing of real-time streaming data directly into Apache Iceberg on OSS.

Abstract Alibaba Cloud EMR Serverless StarRocks is a fully managed, storage-compute-separated lakehouse OLAP engine.

MaxCompute debuts Agentic ecosystem for seamless AI-driven data analysis.

EMR Serverless Spark enables hybrid SQL retrieval in data lake for multimodal AI scenarios.

About Alibaba Cloud E-MapReduce (EMR), an open-source big data platform, is a fully managed cloud-native big data platform built on the open-source ecosystem.
This article introduces how Quick BI's AI assistant "Smart Q" is empowering Shenzhen Water Group to transform its data analysis and drive data-driven decision-making.

At Flink Forward Asia 2026, Alibaba Cloud shared plans to push Apache Flink towards “agentic streaming”, driven by the rise of agents and multimodal data in the agentic AI era.

This article introduces how Quick BI and its AI agent Smart Q empower cross-platform quantitative trading with AI-native analytics.

Flink Agents brings AI agents into the Flink streaming pipeline — an agent becomes a first-class operator in your real-time datastream.

This article introduces the Quick BI V6.2 upgrade that deeply integrates AI into enterprise data decision-making workflows.

May 2026 Alibaba Cloud Big Data & AI Newsletter: Tech updates, new releases, market trends, and customer practices.

Traditional streaming data pipelines often need to join many tables or streams on a primary key to create a wide view.

Jark Wu Creator of Fluss project The industry is undergoing a clear and significant shift as big data computing transitions from offline to real-time processing.

Apache Fluss and Paimon:Fluss delivers sub-second real-time data for Flink (reducing state bloat); Paimon is a streaming lakehouse format with ACID and minute-level latency.

The article introduces Quick BI's Smart Q Skill Package, an AI-native analytics tool that helps ecommerce teams gain actionable business insights via natural language.
Hologres unifies AI-powered ad creative generation and campaign analytics within a single SQL-driven compute engine, closing the loop from "generate →...

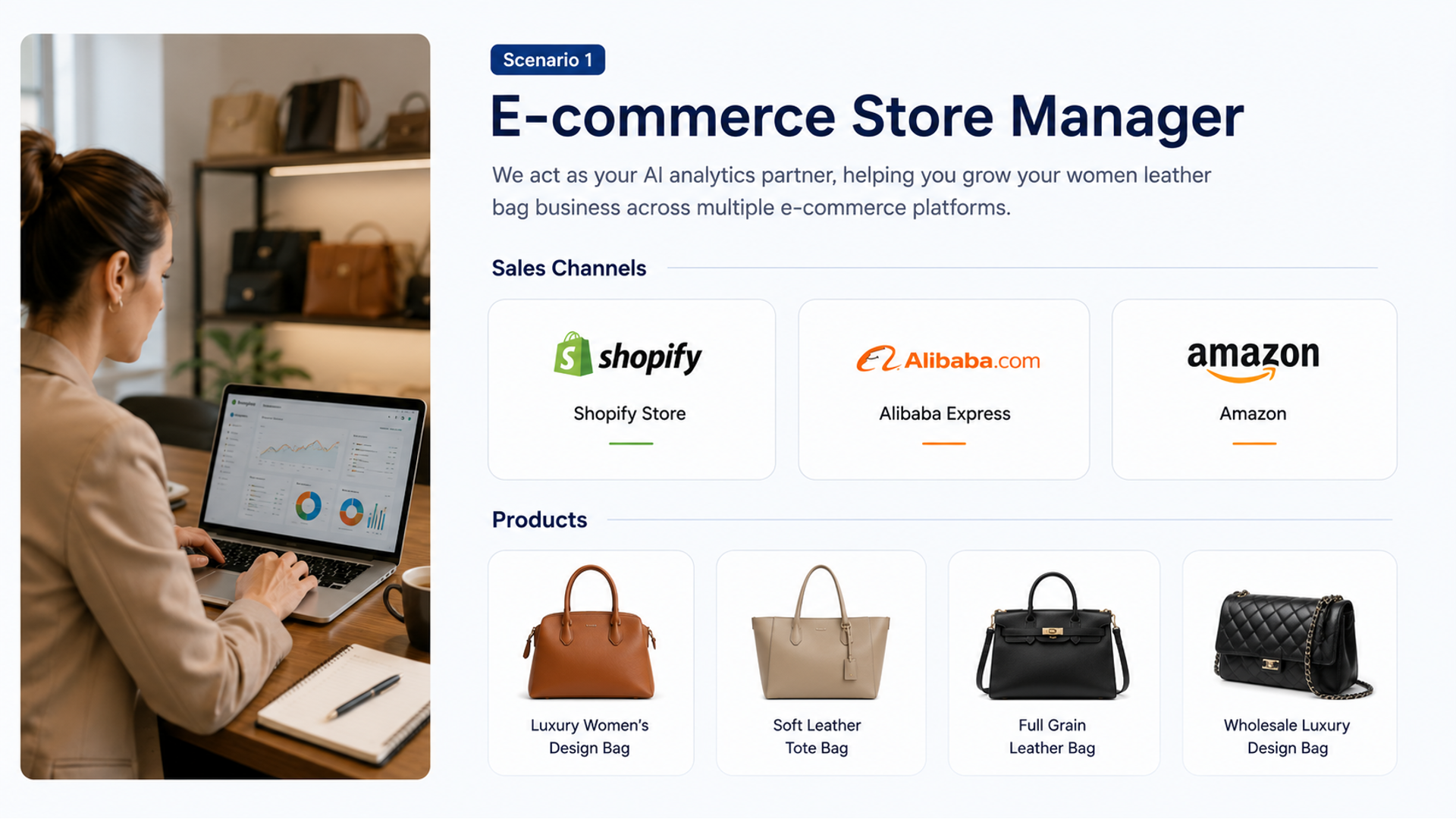
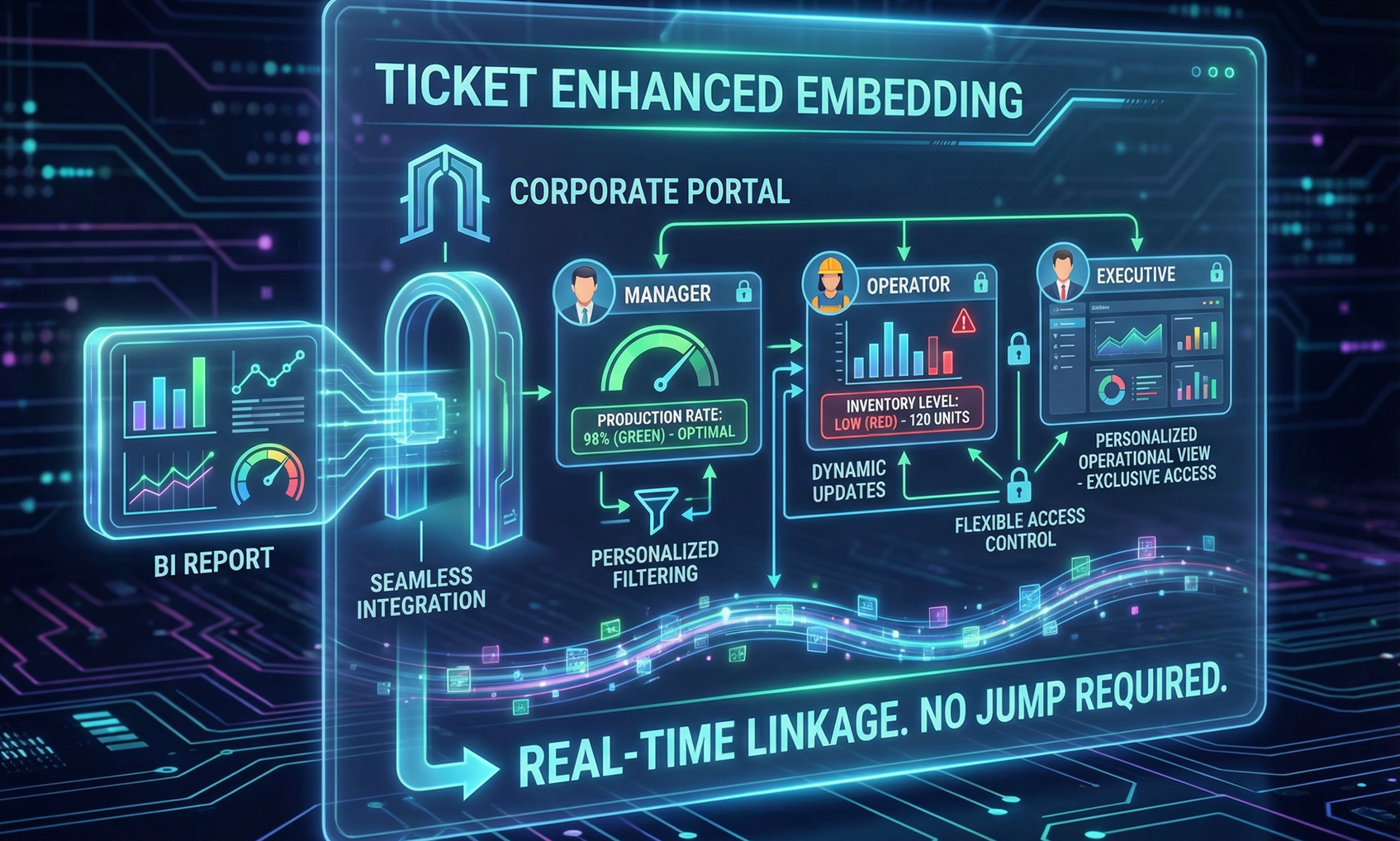
Quick BI's ticket-based enhanced embedding enables secure, personalized data sharing with fine-grained access control.
This article showcases how enterprise-grade data solutions empower AI Agents to deliver trustworthy, actionable business insights.


