This article introduces AliSQL's vector cache design and transaction concurrency mechanisms for production-ready vector search.
This article introduces a dual memory-pool inference framework enabling efficient hybrid Transformer-Mamba model execution by resolving conflicting caching mechanisms.

This article introduces engineering optimizations to 3FS—KVCache's foundation layer—across performance, productization, and cloud-native management for scalable AI inference.

This article introduces HiCache, a hierarchical KVCache infrastructure developed by Alibaba Cloud Tair and SGLang to optimize performance and memory capacity for long-context "agentic" LLM inference.

This article summarizes almost everything you need to know about Redis from an incident.

Image optimization is crucial to the performance of e-commerce web pages. This article discusses some simple and reliable image optimization methods.

This article explains how to set up and configure Alibaba Cloud Tair (Redis® OSS-Compatible) in-memory database

This article explains how to use Fluid to implement tiered affinity scheduling and configure custom affinity based on real scenarios.

This article discusses data inconsistency between cache and database and the best choice of solutions in different business scenarios.

This short article discusses the background and technical scheme of EROFS.

This article introduces local cache technology (for general understanding) and then introduces the best-performance cache.

This article introduces Dragonfly2 and some of its new extensions.

This article describes how to measure the access latency at different levels of memory hierarchy and introduces the mechanism behind it.

This article explains ObTableScan design and code knowledge and introduces the analysis of the location cache module.

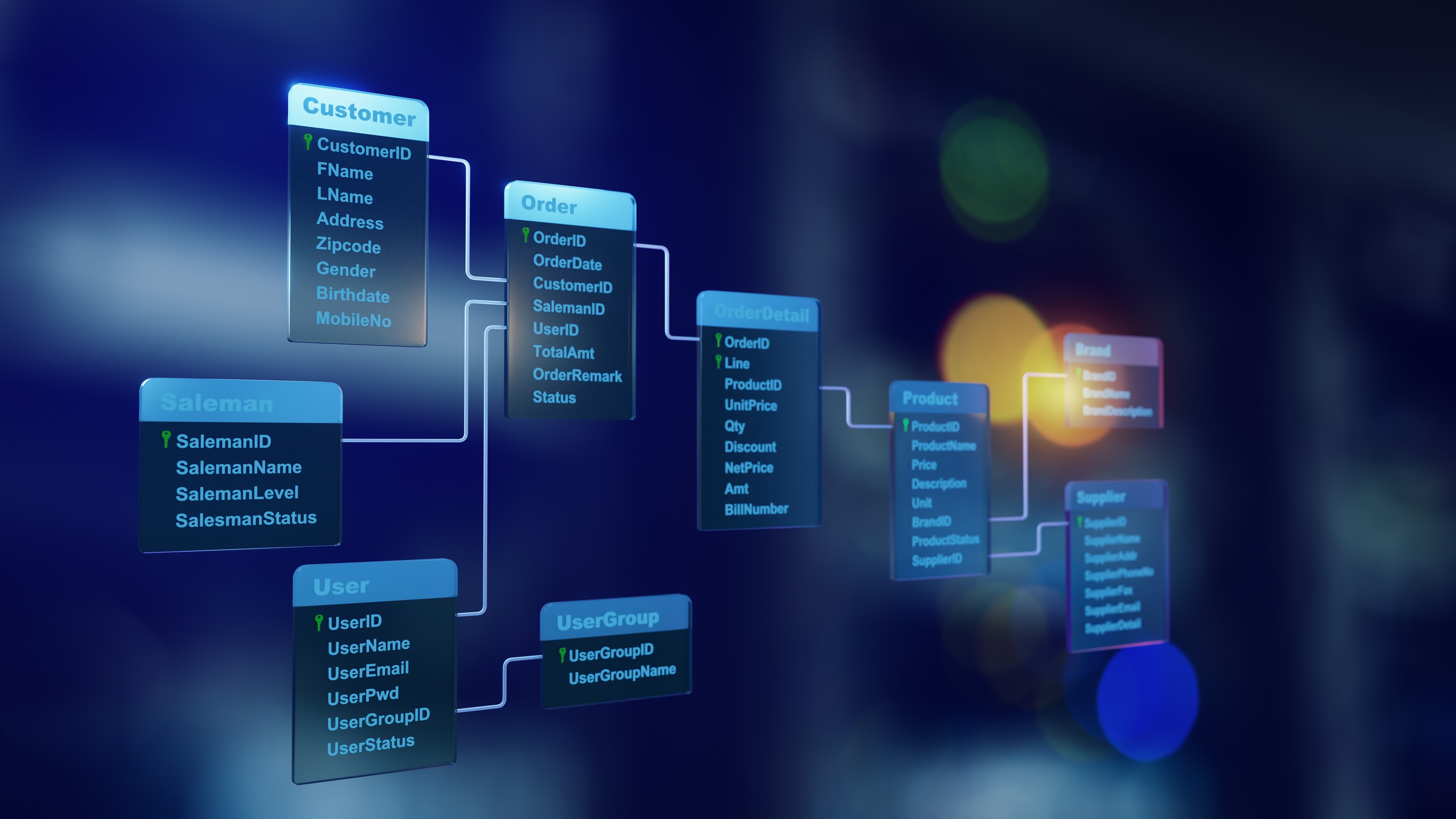
This article focuses on the data structure and implementation architecture of the data dictionary.

This article explains dynamic planning, its concepts, and its processes.

This article shares the optimization techniques of subqueries and tips on handling subqueries in distributed databases.

In this blog, we'll introduce the origins of JindoFS and discuss the problems its

Part 1 of this 2-part series explains Memory Barrier and its associated functions in depth.

Learn how new technologies are accelerating the digital transformation of government agencies and enterprises.


