Learn how to build a Self-Routing Multi-LLM architecture with Alibaba Cloud AI Gateway and Model Studio, covering AI Fallback, operational monitoring, and cost optimization.

Alibaba Cloud AI Gateway와 Model Studio를 활용해 Self-Routing Multi-LLM 아키텍처를 구축하고, AI Fallback, 운영 모니터링, 비용 효율화를 구현하는 방법을 소개합니다.
Python is a must-have skill for network automation professionals. Discover why mastering Python can shape your network automation career, its benefits, and how it integrates with modern networking.

阿里云官方預置鏡像方案,全程零代碼、10分鐘內完成部署,適合零基礎用戶;同時補充手動部署與常見問題排查,確保穩定運行。

This article introduces how to enable an AI assistant to perform real-time tasks by using Function Calling to interact with external tools and functions.

阿里雲內容分發網絡(Alibaba Cloud CDN)。無論您的業務是面向全球用戶的電商平台、新聞媒體、遊戲下載,還是企業官網,CDN都能顯著降低延遲、提高載入速度、節省源站頻寬並增強安全性。本教學將手把手指導您如何在阿里雲國際站完成CDN服務的開通與基礎設定。

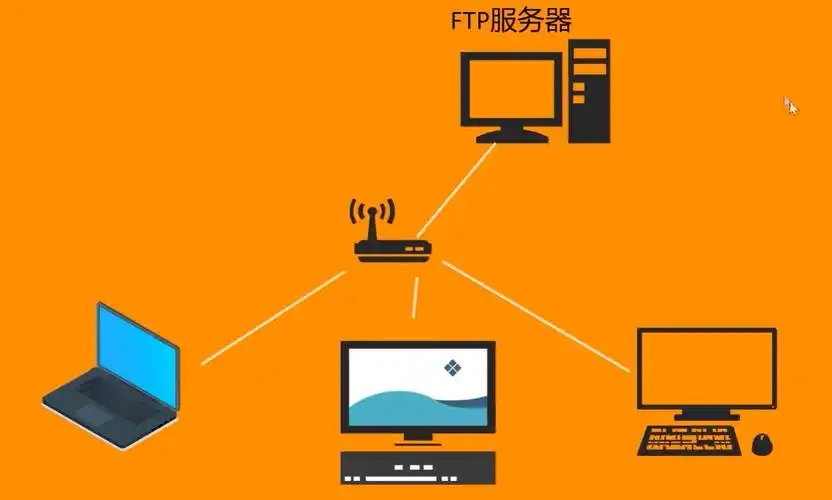
檔案傳輸協定(FTP)作為傳統的網路檔案共享方式,至今仍在許多應用場景中發揮重要作用。本文將詳細介紹如何在Linux環境下部署安全可靠的FTP檔案服務,採用業界廣泛認可的vsftpd服務軟體,幫助您快速建構高效能的檔案傳輸平台。
在數位化浪潮中,一個高效穩定的網站如同企業的「數位門面」。當我們談及自主建站,WordPress憑藉其41%的全球市佔率,始終是開發者的首選方案。但隨著雲端技術演進,「如何在雲伺服器實現企業級WordPress部署」已成為值得深究的課題。

在全球化數位浪潮加速演進的今天,雲端計算服務已成為跨國企業和全球開發者構建數位化業務的核心基礎設施。作為亞太地區領先的雲端服務提供商,阿里雲國際站(Alibaba Cloud International)透過遍佈全球的資料中心和豐富的雲端產品矩陣,為來自200多個國家和地區的企業及開發者提供穩定可靠的雲端服務。

This article describes how to install an Application Real-Time Monitoring Service (ARMS) agent for a Python application.

This article will guide you to use ROS CDK to quickly deploy 2048 games to the cloud.

This article explores the Asset module by walking through a case study of deploying website content to the cloud.
The article explains how to use Python to schedule changes to the maximum and minimum RCUs of an ApsaraDB RDS instance to optimize cost and improve elastic RCU scaling performance.

This article uses SQL Server 2017 as an example to illustrate the configuration steps for the entire migration process.

This article introduces how to create and deploy a basic generative AI model (an autoencoder) on Alibaba Cloud.

This article describes how to use Hera, Argo Workflows SDK for Python, to create large-scale workflows.

This article introduces how to use Fluid and Vineyard for efficient intermediate data management in Kubernetes.

This article introduces how to use common Pandas operators with MaxFrame.

Hướng dẫn Sử dụng Alibaba Cloud Model Studio với Python SDK tạo chatbot đơn giản như GPTChat

แนะนำทุกขั้นตอนตั้งแต่การเปิดใช้งาน Model Studio การติดตั้ง SDK บน Ubuntu ไปจนถึงการเขียนโค้ด Python เพื่อทดสอบความสามารถของ Qwen-Max


