This article explains how Alibaba Cloud NAT Gateway uses SNAT and DNAT to mediate traffic between private VPC workloads and the public internet, and the decisions that shape a sound deployment.

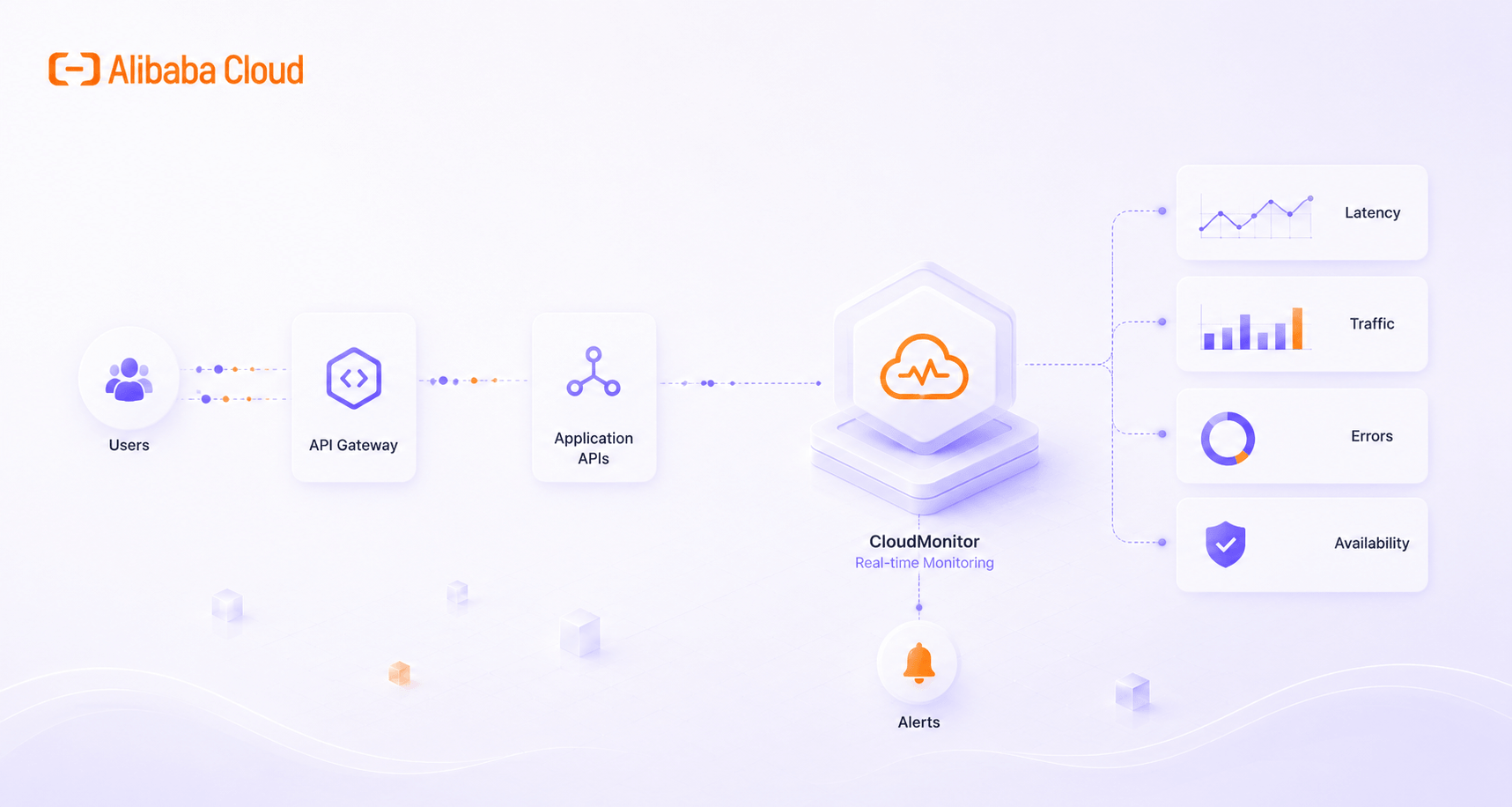
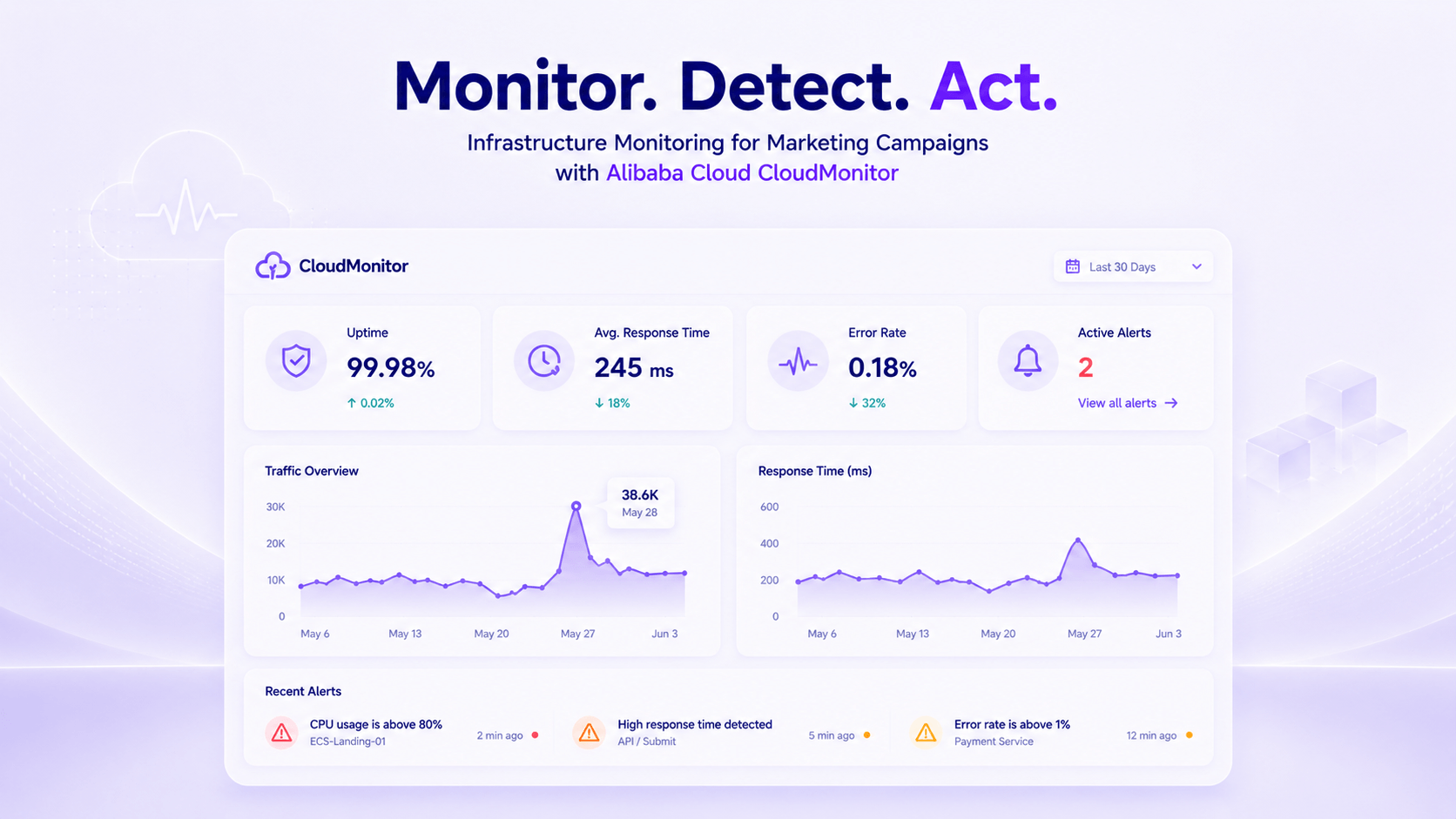
Learn how to monitor API performance for digital marketing platforms using Alibaba Cloud CloudMonitor to improve reliability, detect issues early, and maintain stable campaign operations.
Learn practical ways to reduce Alibaba Cloud costs using smarter scaling, infrastructure monitoring, and storage optimization strategies for small teams.
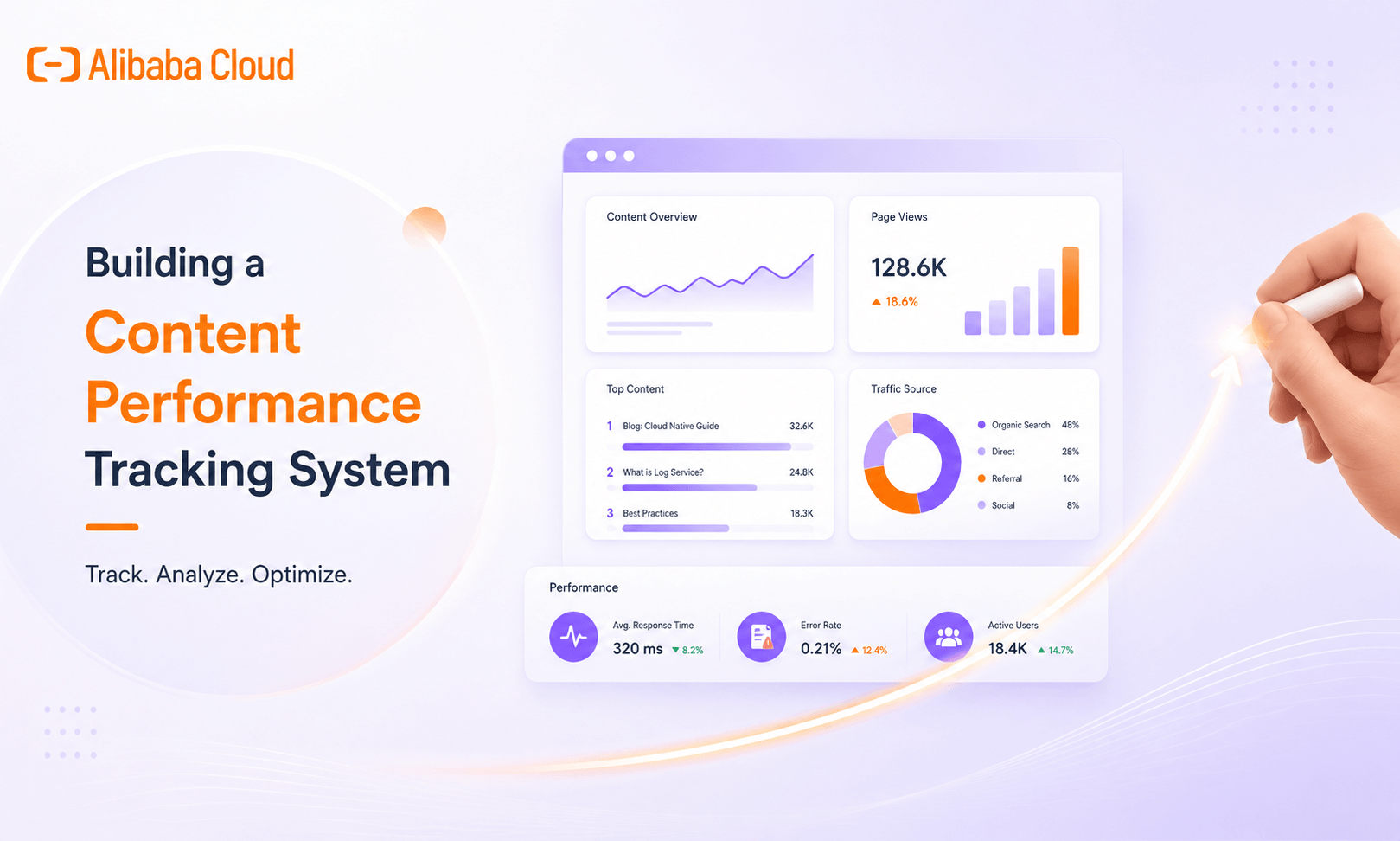
A practical guide to building a scalable content analytics and monitoring system using Alibaba Cloud Log Service to track traffic, engagement, operati.
Learn how to use Alibaba Cloud CloudMonitor to monitor marketing infrastructure, track landing page performance, detect traffic spikes, configure aler.
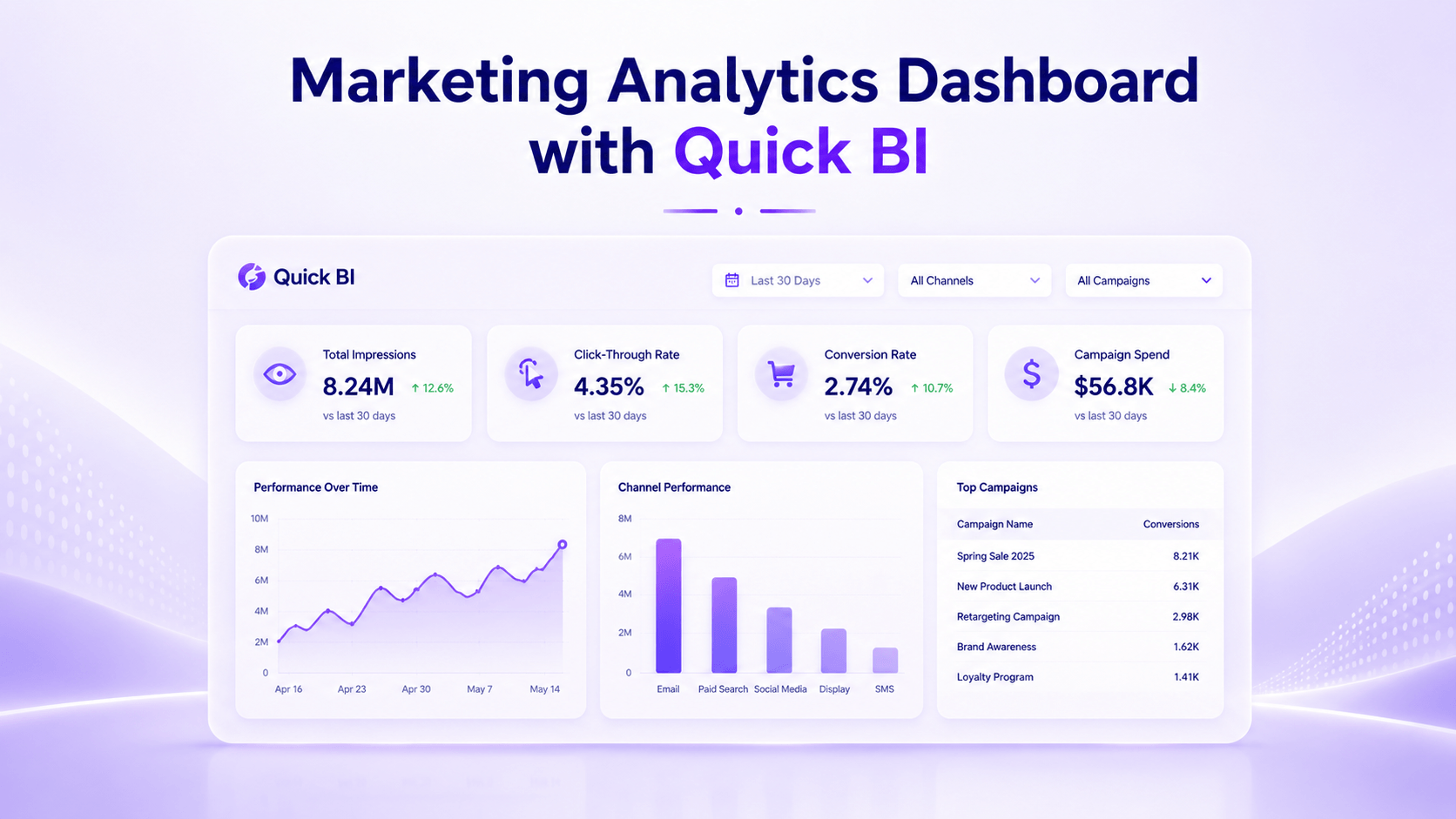
Most marketing teams lack dedicated analysts, making data-driven decisions harder. This guide shows how to use Alibaba Cloud Quick BI to connect campa.
Modern digital advertising systems process massive volumes of campaign data, analytics events, and automation tasks every day.

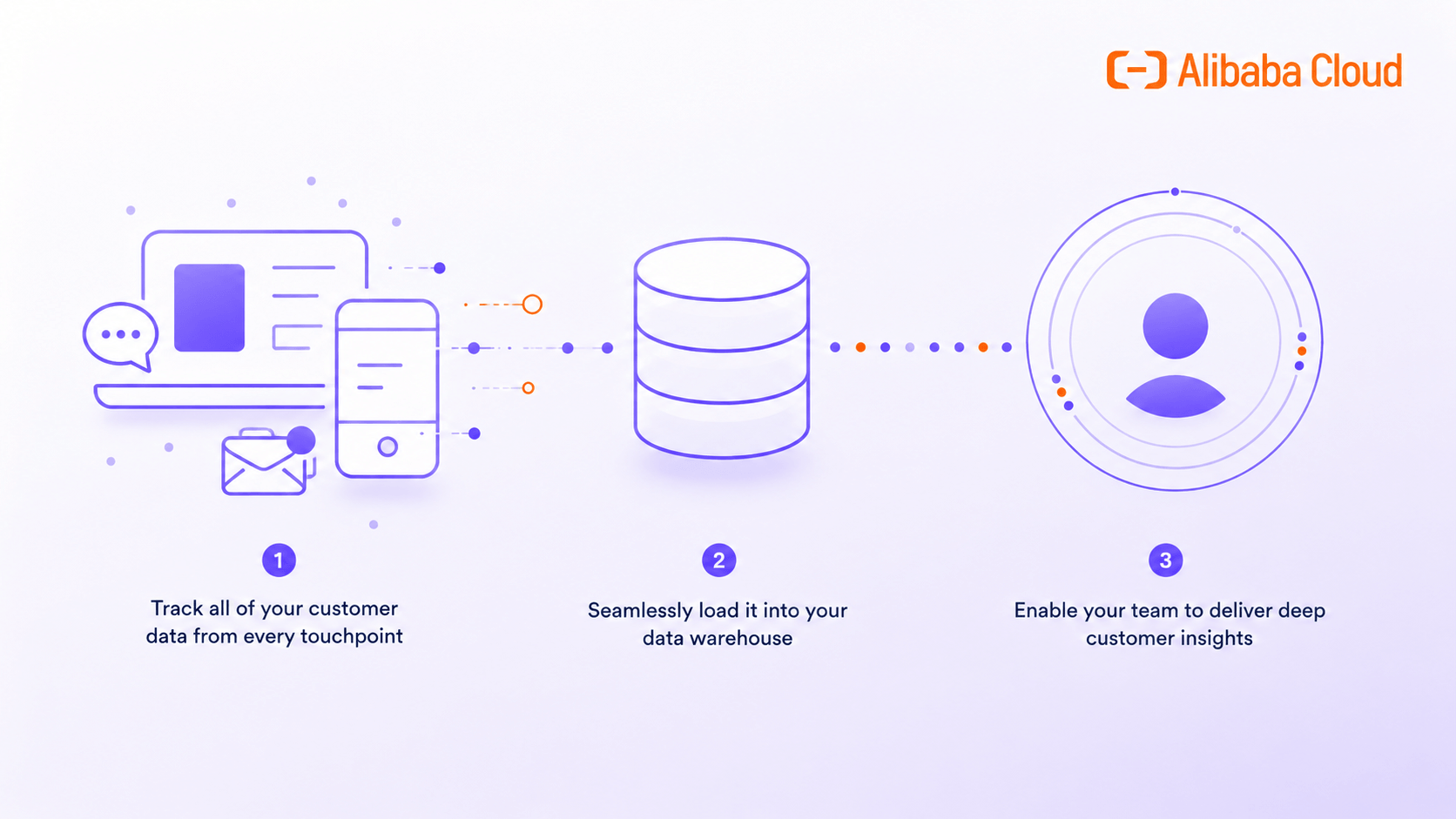
Learn how to build a Customer Data Platform (CDP) on Alibaba Cloud using DataWorks, MaxCompute, ApsaraDB RDS, and OSS to unify customer data, create e...
Learn how to build an AI-powered marketing chatbot with Alibaba Cloud Model Studio using no-code agents, RAG knowledge bases, and Qwen models to deliv.

This article is a practical guide to migrating file storage from local disks to Alibaba Cloud OSS, covering bucket setup, SDK usage, security, and cost optimization.

Protect your cloud environment by preventing attacks on exposed RDP and SSH ports. Alibaba Cloud Firewall helps secure access with strict allow-lists, traffic monitoring, and layered controls.

How to Automate Email and SMS Marketing Campaigns with Alibaba Cloud Direct Mail and DataWorks, spend more time managing data and campaigns than on strategy.

Cloud-based verification on Alibaba Cloud keeps your lists clean, reduces bounces, and protects sender reputation.
A reference architecture guide for building scalable, secure eCommerce customer support on Alibaba Cloud — covering five system layers, key services, .

Learn how AI agents integrate with cloud computing using Alibaba Cloud. This blog covers the basics, real-world use cases, and simple steps to build a.

TL;DR: Build your own AI-powered B2B lead intelligence system on Alibaba Cloud using DataWorks, OSS, AnalyticDB, PAI, and Quick BI to automate lead co.

This article examines how Alibaba Cloud RocketMQ functions as the message buffer layer between IoT Platform and downstream consumers, enabling durable...

This article explores three fast-growing AI marketing channels and how Alibaba Cloud helps businesses use them to work smarter and reach more people.

This article introduces a unified observability architecture for cross-cloud log analysis and AIOps, designed to streamline multicloud O&M and reduce costs for global enterprises.

Proactive transcoding + container-native pipelines = dramatic cloud resource optimization. Implement proven cloud optimization services and cloud infrastructure optimization at scale.


