AliSQL enhances MySQL with DuckDB-powered analytical instances for high-performance HTAP capabilities while maintaining full MySQL compatibility.

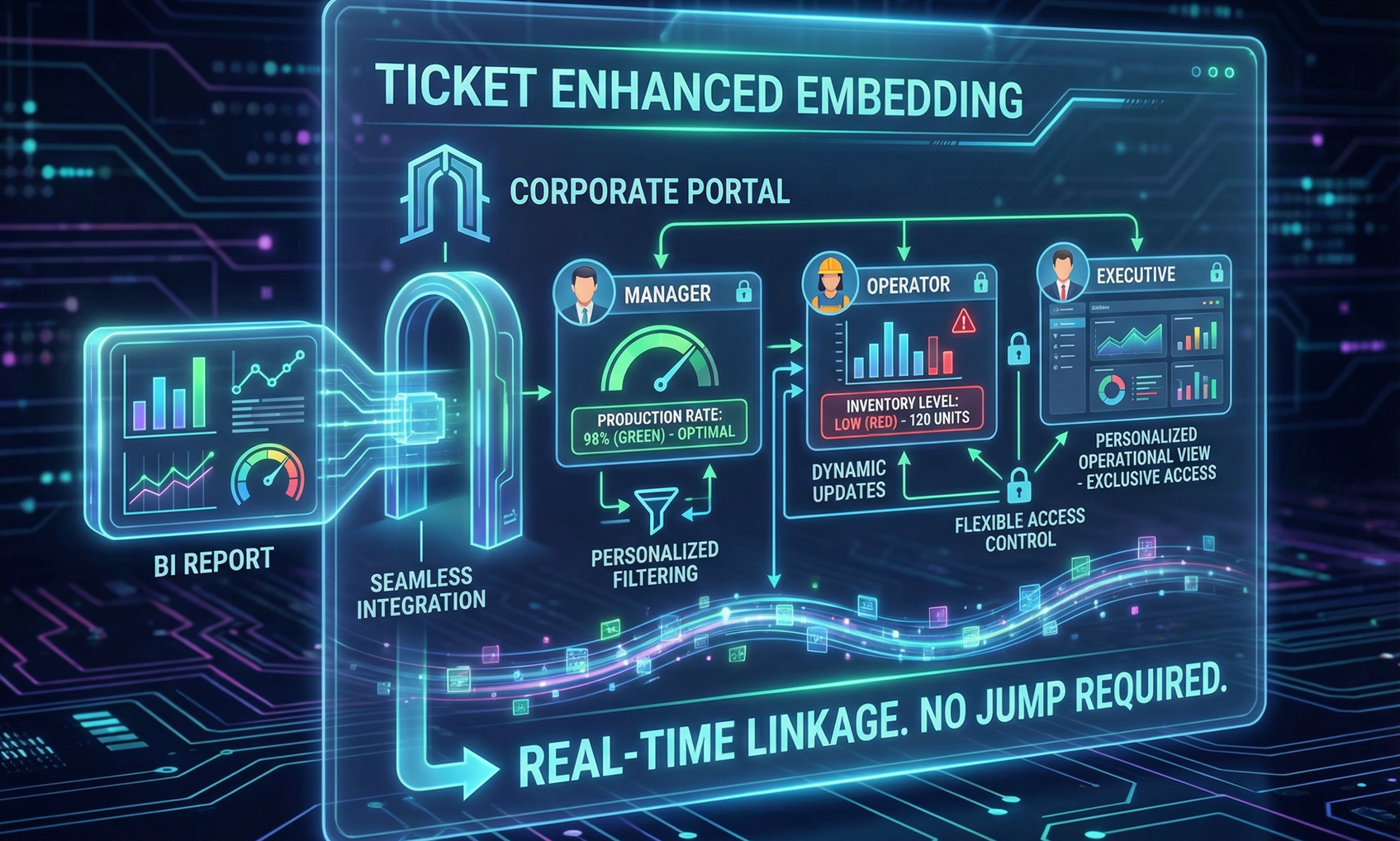
Quick BI's ticket-based enhanced embedding enables secure, personalized data sharing with fine-grained access control.
This article showcases how enterprise-grade data solutions empower AI Agents to deliver trustworthy, actionable business insights.

Quick BI Embedded Analytics delivers role-based, authentication-free report embedding for personalized, seamless data experiences.

This article introduces how BaoZun leverages Alibaba Cloud's Quick BI to empower its portfolio of 490+ premium brand clients.

This article explains how AliSQL natively supports high-density storage and efficient analysis by deeply integrating DuckDB while maintaining compatibility with the MySQL ecosystem.

AliSQL integrates DuckDB as a storage engine to add high-performance OLAP capabilities to MySQL while maintaining full compatibility.

This article introduces how Alibaba Cloud ApsaraDB Data Agent achieved dual breakthroughs in performance and user experience for AI-powered data analytics.

This article introduces Quick BI Enterprise Standard Version's evolution from static dashboards to an intelligent, closed-loop decision-making engine.

This article introduces how Hailiang Group leverages Quick BI and Hailiang Brain to build a "See–Know–Act" data-driven decision engine across HR, marketing, and logistics.

This article introduces the Quick BI V6.1 upgrade, highlighting its new Intelligent Relational Model and AI capabilities that enable zero-threshold data modeling and intelligent analysis.

This article introduces how ad hoc analysis eliminates data-waiting bottlenecks and empowers business teams to make faster, data-driven decisions.

This article introduces how Heaven Gifts used Alibaba Cloud Quick BI to break down global data silos and achieve a 50% increase in operational efficiency.

This article introduces how Alibaba Cloud’s tailored, secure, and scalable cloud infrastructure empowers fast eCommerce growth in emerging markets.

This article explores how the ELT (Extract, Load, Transform) approach modernizes data pipelines, offering greater scalability, flexibility, and speed for today's demanding analytics workloads.

Learn Apache Flink FLIP-15 smart iterations with StreamScope and intelligent termination. Master backpressure optimization, deadlock prevention, and advanced loop processing for real-time analytics.

This article introduces how stream data analytics empower businesses to harness real-time data for faster, smarter decision-making and enhanced competitiveness.

We will first introduce the business background of Alibaba Mama's advertising platform, then explore the design and evolution of its real-time advertising system and data lake architecture.

Master Flink SQL fundamentals with Stream-Table Duality, event time, and watermarks. Build unified stream-batch processing pipelines for modern data engineering.

Discover vivo's real-world Lakehouse integration using Apache Paimon. Learn architecture design, performance optimization, and unified stream-batch processing.


